어떻게 선택하더라도 우연의 일치에 의해 일어나는 효과를 모두 제거할 수는 없다
<The Design of Experiments>, 로널드 A.피셔
귀무가설, 대립가설?
가설검정(hypothesis test)은 처음 접할 땐 사고과정이 난해하여 통계학 중에서도 어렵다는 평가를 많이 받는 방식이다. 가설검정의 대략적인 방식은 다음과 같다. 먼저 가설을 세우고, 해당 가설이 옳다고 가정한 뒤 '확률적으로는 거의 일어나지 않을 일'이 일어나면 그 가설을 부정하고 반대의 가설을 채택한다. 즉, 가설 A가 올바르다고 가정했을 때, 확률적으로 아주 희귀한 일이 발생한다면 가설 A 자체가 잘못되었을 가능성이 크다는 것으로, 최초의 가설 A를 부정하고 그 대안으로 다른 가설 B를 채택한다는 원리다. 쉬운 예를 통해 이해해보자.
동전 앞면이 나올지 뒷면이 나올지에 따라 돈을 거는 도박판이 있다고 가정하자. 일반적으로 동전 던지기에서 앞면, 뒷면이 나올 확률은 각각 1/2다. 여기서 도박 딜러가 "전 '뒷면'에 계속 걸겠습니다. 제가 이길 확률은 1/2에 지나지 않아요. 누군가 '앞면'에 걸 사람 없나요? '앞면'에 걸어서 이긴 분께는 3배인 3000원을 드리죠."도박이 시작되자, 어째서인지 뒷면만 3번 연속으로 나오는 바람에 딜러 혼자 계속 이기게 되고 모두가 수상하다고 생각했다.
출처 : '이렇게 쉬운 통계학'(한빛미디어)
이 상황에서 동전의 앞면에 돈을 건 사람들은 "이건 사기 동전이야!"라고 주장한다. 그리고 이를 검증하고 싶어할 것이다. 이때 검증하고자 하는 것을 대립가설(H1)이라고 부른다. 하지만, 도박 딜러는 사기 동전이 아니라 정상적인 동전이라고 주장한다. 이때 딜러의 주장을 귀무가설(영가설, H0)이라고 한다. '처음부터 쓸모없음을 확인하고자 검증하는 가설'이라는 의미를 지닌다.
유의성 검증은 '귀무가설이 옳다면 발생하기 매우 희박한 현상을 관측했으니 새로운 가설이 필요하다'라는 논리가 기본 전제다. 중요한 것은 일단 최초의 가설인 귀무가설을 옳다고 '가정'하고 출발한다는 것. 만일, 귀무가설을 반박할 희귀한 사건이 발생한다면 새로운 대안이 필요한데, 이 대안으로 상정되는 가설을 대립가설이라고 한다. 여기서의 대립은 'alternative'다. 이런 이유로 대립가설은 alternative hypothesis라고 한다. 즉, 대안가설인 셈이다.
유의수준, 기각역
여기서 중요한 점은 결국 '지극히 희귀한, 드문' 경우의 기준을 구체적인 수치(확률)로 사전에 정의해두는 것. 그렇게 결정한 수치(확률)보다 작은 확률의 일이 발생했을 때 더는 '우연'이라 할 수 없고 무언가의 필연적인 의미가 있을 것이라고 선을 그은 기준(확률)을 유의수준(Significance level)이라 한다.
좀 더 쉽게 말하자면 다음과 같다.

귀무가설(이 동전은 사기가 아니다)을 일단 '옳다'라고 가정했을 때, 확률적으로 일어날 수 없는 '아주 희귀한 일'이 발생한다면 귀무가설(이 동전은 사기가 아니다)은 그 자체로 잘못되었을 가능성이 크다. 여기서 '아주 희귀한 일'을 구체적인 수치(확률)로 기준선을 정해주는데 이 기준선을 '유의수준'이라고 하는 것이다. 일반적으로 유의수준(알파값이라고 한다)은 5%(0.05)로 설정한다. 이 유의수준에 포함되면 '가설이 옳다고 가정했을 때 부자연스럽게 드문 일이 일어났다.'라고 보고 '최초의 가설(귀무가설, 영가설)'을 버린다.
귀무가설을 버리는 것을 통계학에선 '기각한다'라고 표현하며 이 기준선보다 희귀한 방향(지극히 드문 영역)을 '기각역'이라고 한다. 위의 그래프에서 노란색으로 색칠된 영역이 바로 기각역! 기각역은 귀무가설이 부정되고 대립가설이 채택되는 영역이다. 기각역의 안쪽이면 대립가설을 채택하고 기각역의 범위의 밖이면 귀무가설을 수용한다.
양측검정(two-sided test), 단측검정(one-sided test)
그렇다면, 기각역은 어떻게 정할까? 가설검정에서 기각역을 정하는 방법에는 정규분포의 양쪽 끝에 설정하는 양측검정과 한쪽 끝에만 설정하는 단측(우측, 좌측)검정이 있다.

(1) 양측검정
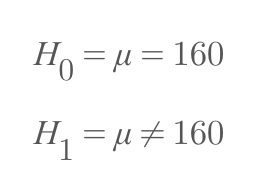
A라는 학급의 평균 키가 160cm이라는 최초의 가설이 있다고 가정하자. 이는 귀무가설이다. 수식으로 표현하면 위의 첫 번째 식과 같다. 이에 대한 대립가설, 즉 우리가 검증하고 싶은 가설은 'A 학급의 평균 키는 160cm가 아니다'라고 해보자. 이를 수식으로 나타내면 위의 두 번째 식과 같다. 양측검정에서는 좌우로 각각 2.5%(0.025)의 기각역(귀무가설이 부정되는 영역)이 설정된다.
(2) 단측검정

이번에는 대립가설이 'A 학급의 평균 키는 160cm보다 작다'라고 해보자. 이를 좌측검정이라고 한다. 반대로 이번엔 'A 학급의 평균 키는 160cm보다 크다'라고 하자. 이를 우측검정이라고 하며 수식은 아래와 같다. 단측검정의 기각역은 5%(0.05)다.

그렇다면, 양측검정과 단측검정 중 어떤 걸 선택하는 게 좋을까? 이는 귀무가설과 대립가설을 설정하는 방법과 목적에 따라 달라진다. 예를 들어, 신약을 개발한다고 해보자. 신약을 개발할 때는 기존의 약물보다 더 좋은 효과를 기대한다. 이때의 대립가설은 '신약이 기존의 약보다 효과가 좋다'인데, 이 경우엔 양측검정이 아닌 단측검정으로 검정하면 된다.
가설검정 순서
(1) 대립가설 설정
(2) 귀무가설 설정
(3) 귀무가설이 옳다고 가정
(4) 유의수준 설정 (보통 5%)
(5) 대립가설을 고려한 기각역 설정
(6) 데이터로 판단
(7) 기각역 안쪽 -> 귀무가설 기각하고 대립가설 채택
(8) 기각역 밖 -> 귀무가설 수용
가설검정을 위해선 유의확률을 계산해야 한다. P값, P-value라고도 부르는 유의확률은 귀무가설이 옳다고 가정할 때 얻은 결과보다 극단적인 결과가 실제로 관측될 확률이다. 즉, 검증통계량(Z값)이 실제 관측된 값보다 대립가설을 지지하는 방향으로 더욱 치우칠 확률이며, 이 값이 작을수록 귀무가설에 대한 반증의 강도가 세다. 유의확률이 유의수준 알파값 이하이면, '귀무가설은 기각될 수 있으며 대립가설이 통계적으로 유의하다'라고 판단한다.
반면, 유의확률을 계산하지 않고 귀무가설의 기각 여부를 판단할 수 있다. z값을 구한 후, 유의수준 0.05의 백분위수인 1.645와 z값을 비교하면 된다. 즉, z값이 기각역 범위에 포함되는지 포함되지 않는지 그림으로 그려서 판단하면 편하다.
귀무가설이 참인데 기각하면? 1종의 오류
|
|
H0가 참
|
H1가 참
|
|
H0을 기각안함(H0 수용)
|
옳은 결정(1-알파)
|
제 2종의 오류(베타)
|
|
H0을 기각
|
제 1종의 오류(알파)
|
옳은 결정(1-베타)
|
유의수준 알파값은 귀무가설이 참일 때 귀무가설을 기각하고 대립가설을 채택하는 '제 1종의 오류'를 범할 확률과 같다. 즉, 유의수준을 5%(0.05)로 설정한다는 것은 제 1종의 오류를 범할 확률의 허용한계를 5%로 정한다는 것을 의미한다. 반면, 제 2종의 오류는 실제로 거짓인 귀무가설을 기각하지 않고 수용하는 오류로 베타값이다. 베타값은 알파값과 트레이드오프(trade-off) 관계로, 하나의 값이 줄어들면 다른 한 값이 증가한다.
따라서, 제 1종의 오류와 제 2종의 오류를 동시에 줄일 수는 없으므로 상황에 맞는 적절한 유의수준을 정해야 한다.
'Product Analytics > Statistics' 카테고리의 다른 글
| [Stat] 베이즈 정리를 위한 전확률 공식(formula of total probability) (3) | 2024.12.24 |
|---|---|
| [Stat] '표본평균은 모평균과 같지 않다' 표본평균과 표본평균의 평균, 표준오차와 중심극한정리(CLT) 개념 파악하기 (3) | 2024.12.24 |
| [Stat] 회귀모형 평가하기 - RMSE(평균 제곱근 오차) (2) | 2024.12.24 |
| [Stat] 선형회귀(linear regression), 최소제곱법 (0) | 2024.12.24 |