교차검증 (cross-validation)
scikit-learn의 train_test_split()함수를 사용하여 데이터를 훈련 세트와 테스트 세트로 한 번 나누는 것보다 더 성능이 좋은 평가방법은
교차검증.
"Cross Validation"
이다. K-겹 교차검증에서 K에는 5 or 10과 같은 특정 숫자가 들어가며 데이터를 비슷한 크기의 집합 'K개'로 나눈다.
이를 폴드(fold)라고 한다.
(1) 단순 교차검증 cross_val_score
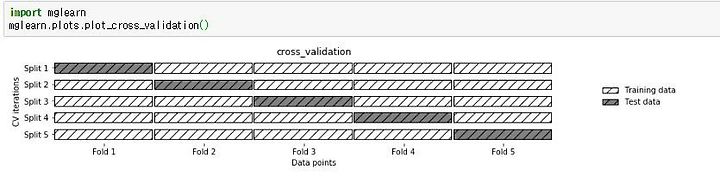
k=5일 때, 즉 데이터를 5개의 부분 집합으로 분할한 후, 각 분할마다 하나의 폴드를 테스트용으로 사용하고 나머지 4개의 폴드는 훈련용으로 쓴다. 이 과정을 반복하여 각 분할마다 정확도를 측정한다.
사이킷런에서는 교차검증을 위해 cross_val-score 함수를 제공한다. 사이킷런의 iris 데이터로 구현해본다.
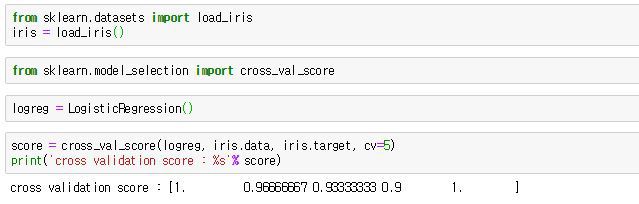
cross_val_score에 들어가는 매개변수는 (모델 명, 훈련데이터, 타깃, cv)인데, 여기에서 cv는 폴드(fold)수를 의미한다. 기본 default는 3이고, 그림처럼 cv=5를 해주면 '5-겹 교차검증'을 하라는 의미가 된다.
최종적으로 평균을 내어 정확도를 간단히 한다.

(2) 계층별 k-겹 교차검증
데이터가 편항되어 있을 경우(몰려있을 경우) 단순 k-겹 교차검증을 사용하면 성능 평가가 잘 되지 않을 수 있다.
따라서 이럴 땐 stratified k-fold cross-validation을 사용한다.
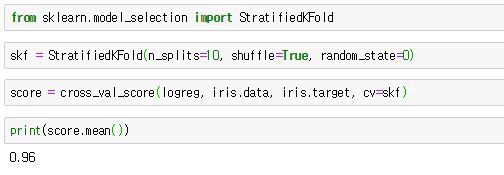
StratifiedKFold함수는 매개변수로 n_splits, shuffle, random_state를 가진다.
n_splits은 몇 개로 분할할지를 정하는 매개변수이고, shuffle의 기본값 False 대신 True를 넣으면 Fold를 나누기 전에 무작위로 섞는다. 그 후, cross_val_score함수의 cv 매개변수에 넣으면 된다.
★ 참고!
일반적으로 회귀에는 기본 k-겹 교차검증을 사용하고, 분류에는 StratifiedKFold를 사용한다.
또한, cross_val_score 함수에는 KFold의 매개변수를 제어할 수가 없으므로, 따로 KFold 객체를 만들고 매개변수를 조정한 다음에 cross_val_score의 cv 매개변수에 넣어야 한다.
(3) KFold 상세조정
cross_val_score함수에서는 cv로 폴드의 수를 조정할 수 있었다.
반면, 위에서 StratifiedKFold의 매개변수를 조정하고 이를 skf에 넣은 후, cross_val_score의 cv에 전달했었다.
이렇게 cv 매개변수로 전달되는 것을 '교차 검증 분할기'라고 하는데, 이를 통해 데이터 분할을 좀 더 세밀하게 할 수 있다.

(4) 임의분할 교차검증(shuffle split cross validation)
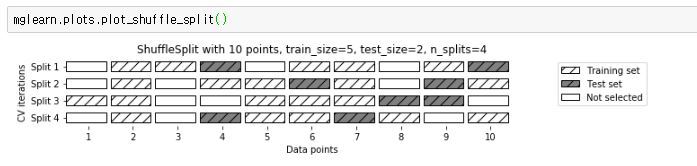
임의분할 교차검증은 train set과 test set의 크기를 유연하게 조절해야 할 때 유용하다.
train_size와 test_size에 정수를 입력하면 해당 수 만큼 데이터포인트의 개수가 정해지며,
만일 실수를 입력하면 비율이 정해진다.

train_size를 전체데이터의 50%, test_size를 전체데이터의 50%로 설정하고, 8번 반복분할하고 실행 때마다 같은 결과가 나오도록 했다.
이 외에도 그룹별 교차검증, LOOCV 등이 있는데, 다음 기회에 살펴보도록 하겠다.
(참고 : introduction to machine learning with python)